Understanding Alerts
When a problem occurs at a datacenter, Application, or SLA, the Monitoring Station can send alerts to users. Alerts are notifications that inform users who are configured to receive alerts of the problem. The notification message contains the following information:
- the type of notification, either Problem or Recovery
- the date and time when the problem occurred
- the name of the host on which the problem occurred
- the status of the host (see Understanding the Status of Services for more information)
- the name of the service that is experiencing the problem
- the current state of the service
- any output from the monitor
Whenever the status of an Element changes (for example, from Critical to Warning), Uptime Infrastructure Monitor sends an alert.
You can also configure alert escalations that occur if a warning is sent and is not acted upon. For example, if an alert is sent to a system administrator, and the administrator does not attend to the problem within a specified amount of time, then the alert is sent to the administrator’s manager.
Uptime Infrastructure Monitor can send alert to a phone, pager, or one or more email addresses.
The following is a sample email alert:
Notification type: Problem 1/12/2008 10:52 Host: filter Host State: N/A Service: FS Capacity - Filter Service State: WARN/ Output: /var is 92% full
The following is a sample pager alert:
subject: CRIT Alert content: 5/7/2005 13:22 Type: Problem Service: FTP (CRIT) Host: filter (CRIT)
Understanding the Alert Flow
Alerts in Uptime Infrastructure Monitor follow a specific flow. When Uptime Infrastructure Monitor detects a problem with a host, it issues an alert. Uptime Infrastructure Monitor then continues to check the host at specific intervals and reports on the status of the host.
Considering the following example:
- Uptime Infrastructure Monitor checks the host system every 15 minutes
- alerts are sent continually every check interval until Uptime Infrastructure Monitor detects a change in the state of the host system
- whenever an error is encountered, Uptime Infrastructure Monitor rechecks the system every minute
- if all rechecks up to the maximum number of rechecks fails, Uptime Infrastructure Monitor issues an alert
Uptime Infrastructure Monitor encounters a critical error on a host. Uptime Infrastructure Monitor performs three rechecks at one minute intervals–all of which return a critical error–and then sends an alert after the third recheck.
Uptime Infrastructure Monitor then checks the host every two hours. While Uptime Infrastructure Monitor encounters two critical errors, it does not send an alert. Then, the status of the host changes from Critical to Warning. When this change is detected, Uptime Infrastructure Monitor sends an alert informing recipients of the change in status. When the status of the host changes to OK, Uptime Infrastructure Monitor issues an alert informing recipients that the host has recovered.
This alert flow is illustrated in the following diagram:
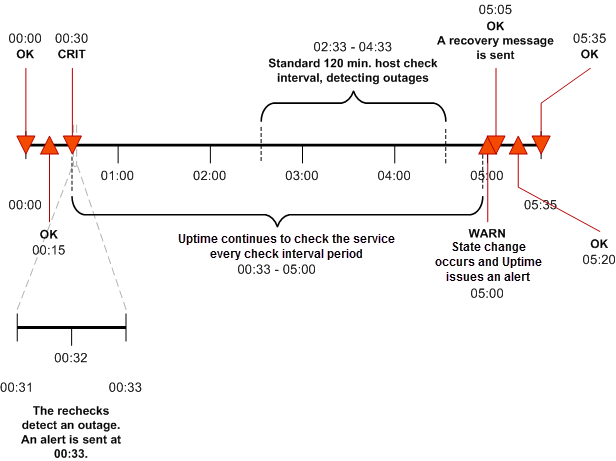
All service monitors have a common set of Monitor Alert Settings that configure aspects of the alert flow.
Alert Profiles
Alert Profiles are templates that tell Uptime Infrastructure Monitor how to react to various alerts that are generated by service checks. Alert Profiles enable Uptime Infrastructure Monitor to execute a series of actions in response to the failure of a service check or when a threshold is exceeded. The following diagram illustrates how an Alert Profile works:
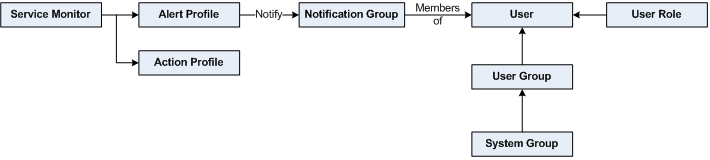
An Alert Profile can send an alert via email, or to a pager or a cell phone. You can configure any or all of these actions to occur simultaneously by associating the Alert Profile to multiple Notification Groups. For example, if a Web server process stops responding, both the system administrator and Web server administrator can be notified.
Custom Alert Formats and Alert Scripts
Alert Profiles include standard message templates for emails and pagers, which are well suited for most alerting needs. However, you can customize the format of the alert using predefined variables. When creating or configuring an Alert Profile, selecting the Custom Format option provides you with a template to modify, and override the message template for the alert type you have selected: 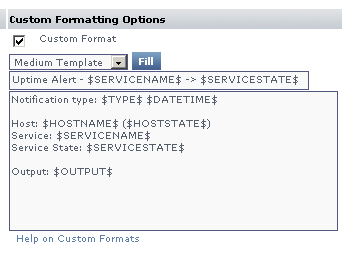
See Custom Alert Message Variables for more information.
In addition to sending alert messages, Uptime Infrastructure Monitor can also execute an alert script. When an outage occurs, the script is run on the Monitoring Station, once for each user who receives notification. Like custom alert messages, alert scripts use predefined variables to represent outage-specific information; these variables are passed to the script at the time of the outage.
For information on alert script variables, see Script Alert Variables. For more information on alert scripts, see the IDERA Knowledge Base article, Creating Custom Alert Scripts in Uptime Infrastructure Monitor Alert Profiles.
Creating Alert Profiles
To create Alert Profiles, do the following:
- On the Uptime Infrastructure Monitor tool bar, click Services.
- In the tree panel, click Add Alert Profile.
The Add Alert Profile window appears. - Type a descriptive name for the profile in the Name of Alert Profile field.
- In the Start alerting on notification number field, enter the number of times an error must occur before Uptime Infrastructure Monitor sends an alert notification.
- Enter the number of times to re-send the notification in the End alerting on notification number field.
You can also select the Never Stop Notifying check box to have Uptime Infrastructure Monitor send notifications indefinitely. - Select one or more of the following notification options:
Email Alert
Sends the alert to the email addresses of the members of a Notification Group.Pager Alert
Sends the alert to the pagers of the members of a Notification Group.Script Alert
Executes an alert script on the Monitoring Station, once for each user who receives notification of the alert.
Because this alert option relies on a script or batch file, enter its name and path in the Script Path field (for example, on Linux,/usr/local/uptime/scripts/scriptAlert.sh).
- If you are using an email or pager notification, and want to use a custom message instead of the standard template, click the Custom Format check box to begin creating a custom alert message. Use the following steps to create the message:
- To expedite message creation, select a Short Template, Medium Template, or Long Template, then click Fill.
- Optionally modify the alert subject header.
- Optionally modify the alert message body.
- Select one or more Notification Groups that receive the notifications.
- Optionally attach this alert profile to one or more existing Service Monitors.
- Click Save.
Viewing Alert Profiles
To view Alert Profiles, do the following:
- On the Uptime Infrastructure Monitor tool bar, click Services.
- In the tree panel, click View Alert Profiles.
The Alert Profiles subpanel appears. The subpanel displays the settings that you configured when you created the profile, as well as a list of the services that are attached to the profile. - To test whether the profile sends alerts, click Test Alert Profile.
A popup window appears, and the alert is sent using the notification method (email, pager, or script) that is specified in the profile. The following is an example of an email alert:
Notification type: Problem 27/4/2006 09:19
Host: Test Host (OK)
Service: Test Monitor
Service State: OK
Output: This is a test notification; please ignore.
When the alert is sent, the messageAlert Profile Testedappears in the popup window. If an error message appears in the popup window, edit the profile and test it again.
Editing Alert Profiles
To edit Alert Profiles, do the following:
- On the Uptime Infrastructure Monitor tool bar, click Services.
- In the tree panel, click View Alert Profiles.
- Click the Edit Alert Profile icon beside the name of the profile that you want to edit.
The Edit Alert Profile window appears. - Edit the Alert Profile fields as described in the section, Creating Alert Profiles.
Associating Alert Profiles to Elements
You can associate an Alert Profile to any Service Monitor, Application, or SLA if their state changes from OK to Warning or Critical. Alert Profiles are normally associated with any of these monitored items at the time of their configuration; you can also modify Alert Profile associations using existing service monitor definitions.
See Using Service Monitors, Working with Applications, and Adding and Editing SLA Definitions for more information about configuring Service Monitors, Applications, and SLAs, respectively.
Action Profiles
Action Profiles are templates that direct Uptime Infrastructure Monitor when it encounters a problem on a monitored system. You can associate an Action Profile to any Service Monitor, Application, or SLA if their state changes from OK to Warning or Critical. Action Profiles are normally associated with any of these monitored Elements at the time of their configuration; Action Profile associations can also be changed when you are modifying existing service monitor definitions.
See Using Service Monitors, Working with Applications, and Adding and Editing SLA Definitions for more information about configuring Service Monitors, Applications, and SLAs, respectively.
Actions include one of the following tasks:
- write an entry to a log file
- run a recovery script that can reboot a non-responsive server; or restart an application, process, or service
- stop, start, or restart a Windows server
- initiate a VMware vCenter Orchestrator workflow
- send an SNMP trap to a specific trap host and trap community
As templates, Action Profiles can be reused for any number of Service Monitor configurations. This means you can create a series of them as standard actions used to respond to typical types of problems you may encounter, depending on what role a Service Monitor is playing (for example, availability or performance).
VMware vCenter Orchestrator Workflow Actions
If an administrator has integrated Uptime Infrastructure Monitor with VMware vCenter Orchestrator (see VMware vCenter Orchestrator Integration), you can configure Action Profiles to initiate Orchestrator workflows.
Orchestrator is a VMware vCenter Server add-on that allows its administrators to create workflows that automate vCenter management tasks. These Orchestrator workflows are open ended: all vCenter actions are available for automation through the processing of parameters and runtime arguments. Uptime Infrastructure Monitor Action Profiles can be configured to provide input parameters to specific workflows, thus integrating vCenter management with Uptime Infrastructure Monitor’s monitoring and alerting capabilities.
For example, if Uptime Infrastructure Monitor is monitoring memory, CPU, and hard disk use for a virtualized server, the passing of performance thresholds can trigger an Action Profile that, in turn, triggers an Orchestrator workflow that creates a new virtual machine to alleviate resource strain. In a converse example, if Uptime Infrastructure Monitor is monitoring a virtualized server for long periods of inactivity, a triggered Action Profile can initiate an Orchestrator workflow that shuts down the instance to free up resources.
By tightly integrating Uptime Infrastructure Monitor’s monitoring and alerting with VMware vCenter Orchestrator’s automated virtual environment administration, you can accelerate your organization’s reaction time with virtual systems management, and map established policies to automated actions.
When configuring Action Profiles, Uptime Infrastructure Monitor communicates with Orchestrator and dynamically produces a list of all available workflows. (This includes any third-party workflow packages that are installed on the Orchestrator server, including the Uptime Infrastructure Monitor Orchestrator package.)
When a workflow is selected, and the Get Parameters button is clicked, the corresponding input parameter fields are dynamically displayed, allowing you to specify parameter values required to completely configure the workflow for execution should an Uptime Infrastructure Monitor alert initiate it.
Orchestrator Input Parameter Variables
When configuring a VMware vCenter Orchestrator workflow, you have at your disposal a set of Uptime Infrastructure Monitor-specific variables that can be entered as parameter variables, and whose ensuing runtime values are passed to the Orchestrator workflow during execution. The variables available to you are those that are used when creating a custom alert format. See Custom Alert Message Variables for information.
SNMP Trap Actions
You can also configure an Action Profile to send an SNMP trap to a particular host. An SNMP trap is a notification issued by a system that is running SNMP when a problem occurs. The host to which the SNMP trap is sent must be running an SNMP trap listener, such as snmptrapd by Net-SNMP. You can use any SNMP trap receiver as long as it can execute scripts when traps are received. When an SNMP trap is sent:
- the SNMP-enabled device sends an SNMP trap to the snmptrapd service
- snmptrapd compares the trap to the list of filters in the snmptrapd.conf file
- when the trap matches the uptime filter, the trap_to_ext_event.pl perl script is executed
- trap_to_ext_event.pl calls the Uptime Infrastructure Monitor API to update the status of the External Check monitor associated with the device
- if an Alert Profile is associated with the monitor, an alert notification is sent out
Below is a diagram depicting the process:
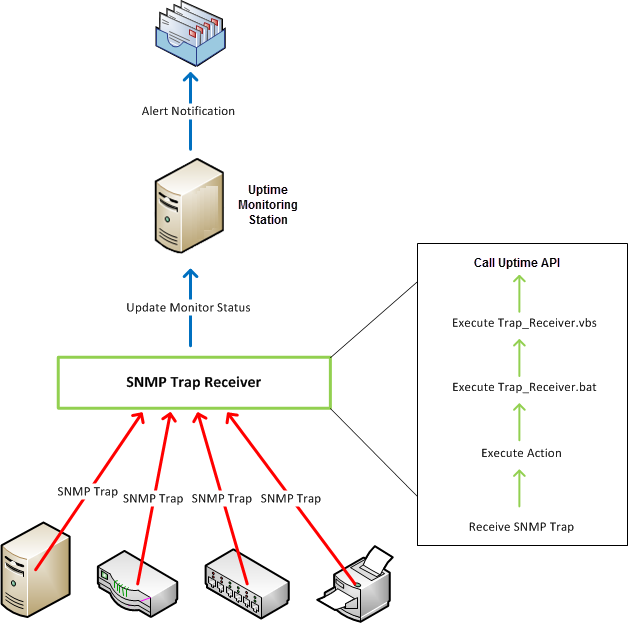
If you use SNMP traps, the trap message is sent in the format specified by the Uptime Infrastructure Monitor MIB. This MIB is found in the /scripts directory. The Uptime Infrastructure Monitor enterprise OID is .1.3.6.1.4.1.24216.
Install Net-SNMP and Perl
- Download Net-SNMP from http://sourceforge.net/projects/net-snmp/files/net-snmp%20binaries/5.6.1.1-binaries/net-snmp-5.6.1.1-1.x86.exe/download
- Download Strawberry Perl from http://strawberryperl.com/download/5.20.1.1/strawberry-perl-5.20.1.1-64bit.msi
- Execute the Net-SNMP installer and accept the defaults.
- Execute the Strawberry Perl installer and accept the defaults
Create a snmptrapd configuration file and Perl script
Create a new file called snmptrapd.conf in the C:\usr\etc\snmp directory with contents similar to the following ("public" on the first line is the SNMP community string - feel free to changed accordingly, and the path to Uptime Infrastructure Monitor on the second line should be changed accordingly):
authCommunity log,execute,netpublictraphandledefaultC:\Strawberry\perl\bin\perl.exe"C:\Program Files\uptime software\uptime\scripts\snmp-trap-script\trap_to_ext_event.pl"- In the Start menu, select the Net-SNMP folder, right click Register Trap Service and choose Run As Administrator
- Start the "Net-SNMP Trap Handler" service
- Create the directory "C:\Program Files\uptime software\uptime\scripts\snmp-trap-script"
- Download and copy this file, trap_to_ext_event.pl, to the directory mentioned in the previous step
This approach assumes that your SNMP trap service monitors all have the same name, "SNMP Trap (member)", and are managed via a Service Group.
There are two logs that are created with this solution, one when traps are received by the Net-SNMP Trap Handler service and another when the trap is sent into Uptime Infrastructure Monitor by the perl script. This helps to narrow down an issue if one arises.
Uptime Infrastructure Monitor Configuration
Create a new monitor called "SNMP Trap" and assign it to a Service Group, so that it can be applied to numerous Elements in Uptime Infrastructure Monitor.
- Create a Service Group for your devices that will send SNMP traps to Uptime Infrastructure Monitor.
- On the Uptime Infrastructure Monitor tool bar, click Services.
- In the tree panel, click Add Service Group.
- Select Regular from the drop-down, and then click "Continue...".
- Enter "SNMP Trap Group" as the name for the Service Group and, optionally, a description for the group.
- In the "Available Element Groups" and "Available Elements" lists, choose the Element Groups and Elements that you want to have SNMP Trap monitors created for.
- Click Finish.
- Create an External Check monitor and assign it to the "SNMP Trap Group" Service Group.
- On the Uptime Infrastructure Monitor tool bar, click Services.
- In the tree panel, click Add Service Monitor.
- Select External Check from the list of available Service Monitors, and then click “Continue…”.
- Input “SNMP Trap” as the Service Name.
- Select the "Service Group" radio button and choose "SNMP Trap Group" from the drop down.
- Choose an Alert Profile to have alert messages sent to the appropriate users.
- Click Finish.
Now when traps are received by the Net-SNMP snmptrapd service, the appropriate "SNMP Trap (member)" service monitor will be set to CRIT and an alert will be sent out. When the status is acknowledged in the Uptime Infrastructure Monitor UI (click the ACK button), the status will be set back to OK.
Creating Action Profiles
To create Action Profiles, do the following:
- On the Uptime Infrastructure Monitor tool bar, click Services.
- In the tree panel, click Add Action Profile.
The Add Action Profile window appears. - Enter a name for this profile in the Name of Action Profile field.
- Specify the number of times an error must occur before Uptime Infrastructure Monitor sends a notification in the Start action on notification number field.
- Specify the number of times actions are carried out in the End action on notification number field.
Optionally, select the Never Stop Notifying option to continually carry out the action in this profile until the problem is resolved. - If VMware vCenter Orchestrator integration is enabled, and you want the Action Profile to drive an Orchestrator workflow, use the following steps:
- In the Select Workflow field, input a workflow to configure.
You can either scroll through and select the workflow from the drop-down list, or begin typing the workflow’s name. - Click Get Parameters.
Uptime Infrastructure Monitor retrieves information from the Orchestrator server and dynamically display configuration fields for the chosen workflow’s input parameters. - Configure the input parameter fields for the workflow.
For information on the specific configuration parameters available for the chosen workflow, consult the appropriate developer’s documentation.
- In the Select Workflow field, input a workflow to configure.
- If you want the Action Profile to write to a log, in the Log File field, enter the name and path to a log file on the Monitoring Station to which error information is written.
- If you want the Action Profile to run a recovery script, in the Recovery Script field, enter the name and path to a script that reboots a server, or restart an application, process, or service.
The recovery script also has the following information appended to it:- the date and time on which the error occurred
- the type of error notification that was sent
- the name of the host on which the error occurred
- the state of the host
- the name of the service that threw the error
- the state of the service
- the output that was generated by the error
for example:"/usr/local/uptime/recover.sh" "24/12/2014 5:01:05" "Problem" "printserver" "null" "WinSrv-Print Spooler" "CRIT/threshold error" "servicestatus: Not Running does not match Running (Service 'Print Spooler' found, status: Not Running, took 12ms)"
For information on predefined variables that can be used in Action Profile scripts, see Recovery Script Variables.
You can also use the recovery script to file trouble tickets with a system like Remedy, or to interact with third-party software packages.
- If you are setting up an Action Profile for a Windows server, you can also leave the Windows Service as Agent, and complete the following fields:
Windows Host
The name of the host on which the service is running.Enter
$HOSTNAME$in this field to create a dynamic hostname. For failing services that call this Action Profile, the corresponding hostname is used when this action runs.You can use this dynamic hostname in conjunction with service groups, where an issue can originate from one of many hosts.
- Agent Port
The port on which the Uptime Infrastructure Monitor agent that is installed on the system is listening. The default is 9998. - Use SSL
Select this option if Uptime Infrastructure Monitor securely communicates with the host using SSL (Secure Sockets Layer). - Agent Password
Enter the password that is required to access the agent that is running on the monitored system. For information on setting the agent password, see the Uptime Infrastructure Monitor Knowledge Base article, What is the password for the Windows agent? Windows Service
The display name of the specific Windows service to which the Action Profile applies. The display name of a service appears in the Name column of the Services Control Panel, or in the Description column of the Windows Task Manager Services tab.The service display name must be entered verbatim, including spaces, otherwise it is not correctly processed. Double-clicking a service name in the Services Control Panel opens a properties window where you can highlight and copy the service Display name.
- Action
Select one of the following actions:- None
- Start
- Stop
- Restart
- If you are setting up an Action Profile for a Windows server that is using a WMI implementation, you can also select the Windows Service as WMI, and complete the following fields:
- WMI Host:
The name of the host on which the service is running. - Windows Domain:
The Windows domain in which WMI is implemented. - Username:
The name of the account with access to WMI on the Windows domain. - Password:
The password for the account with access to WMI on the windows domain. Windows Service
The display name of the specific Windows service to which the Action Profile applies. The display name of a service appears in the Name column of the Services Control Panel, or in the Description column of the Windows Task Manager Services tab.The service display name must be entered verbatim, including spaces, otherwise it is not correctly processed. Double-clicking a service name in the Services Control Panel opens a properties window where you can highlight and copy the service Display name.
- Action
Select one of the following actions:- None
- Start
- Stop
- Restart
- WMI Host:
- If you want to send SNMP traps to a particular host, complete the following fields:
- SNMP Trap Host
The name of the host that monitors SNMP traps. - SNMP Trap Port
The port number on the trap host to which the SNMP trap is sent. - SNMP Trap Community
The name which acts as a password for sending trap notifications to the trap host. - SNMP Trap OID (optional)
The object identifier (OID) that identifies the SNMP trap - for example,.1.3.6.1.2.1.34.4.1.7.
- SNMP Trap Host
- If Splunk integration is enabled, and you want the Action Profile to write to the Splunk log, complete the following fields:
- Splunk Hostname
The host name of the server on which Splunk is running. - Logging Port
The port on which the Splunk server is listening for logging requests. This port is configured in Splunk, and you must contact the Splunk administrator for this information. - Click the Use SSL option to securely access the Splunk server using SSL.
- Splunk Hostname
- Optionally attach this alert profile to one or more existing Service Monitors.
- Click Save.
Viewing Action Profiles
To view Action Profiles, do the following:
- On the Uptime Infrastructure Monitor tool bar, click Services.
- In the Tree panel, click View Action Profiles.
The Action Profiles subpanel appears, displaying the settings that you configured when you created the profile, as well as a list of the services that are attached to the profile. - To test whether the profile works, click the Test Action Profile button.
A popup window appears, and the Monitoring Station tries to carry out the action defined in the profile. When the action is completed, the message Action Profile tested appears in the popup window.
If an error message appears in the popup window, edit the profile and test it again.
Editing Action Profiles
To edit Action Profiles, do the following:
- On the Uptime Infrastructure Monitor tool bar, click Services.
- In the tree panel, click View Action Profiles.
- Click the Edit Action Profile icon beside the name of the profile that you want to edit.
The Edit Action Profile window appears. - Edit the Action Profile fields as described in the section Creating Action Profiles.
Monitoring Periods
Monitoring Periods are the times over which a service monitor is actively monitoring a host. The Monitoring Periods also apply to the times when Uptime Infrastructure Monitor sends alerts
Uptime Infrastructure Monitor comes with the following Monitoring Periods:
- 24x7 – Monitoring is performed 24 hours a day, seven days a week.
- 9am to 5pm weekdays – Monitoring is performed from 9 a.m. to 5 p.m., Monday to Friday.
- Never – No monitoring is carried out.
You can add Monitoring Periods that suit your needs. For example, you can create a Monitoring Period called " Weekends" that only monitors a host from 12:00 a.m. on Saturday to 11:59 p.m. on Sunday.
Adding Monitoring Periods
To add Monitoring Periods, do the following:
On the Uptime Infrastructure Monitor tool bar, click Services.
- In the tree panel, click Add Monitoring Period.
The Add Monitoring Periods window appears. - Type a name in the Monitoring Period Name field.
- In the Definition section, enter one or more time period expressions that combine to create a full Monitoring Period definition.
See Time Period Definitions for information on the types of time period expressions that are valid in Uptime Infrastructure Monitor. - Click Save.